
布隆过滤器解决缓存穿透,高效应对缓存穿透的解决方案
你有没有想过,为什么有时候你访问一个网站,突然间页面就变得超级慢,甚至有时候还会出现“404页面未找到”的情况?这其实是因为缓存穿透的问题。别急,别急,今天就来给你揭秘如何用布隆过滤器这个神奇的小工具来解决这个大麻烦!
什么是缓存穿透?

想象你的电脑里有一个巨大的缓存库,里面存满了各种网页内容,这样你下次访问这些网页时就能瞬间加载,而不是像以前那样慢慢等待。但是,有时候会出现一些“不速之客”,它们试图访问根本不存在的页面,这就好比在图书馆里找一本不存在的书。这些请求就像一把利剑,直接穿透了你的缓存库,导致服务器压力增大,页面加载缓慢,甚至崩溃。
布隆过滤器:缓存穿透的克星
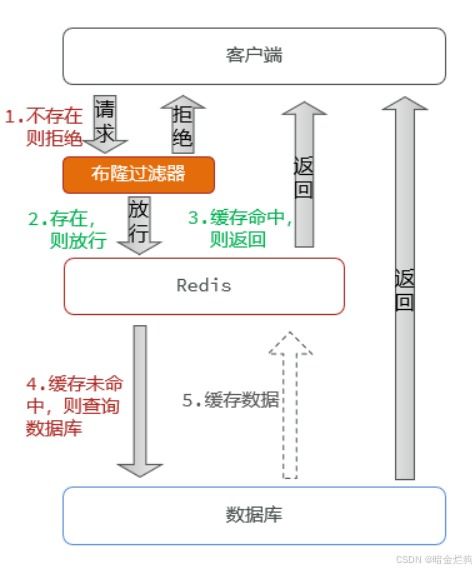
这时候,布隆过滤器就像一位神奇的守门人,站在缓存库的门口,严格审查每一个试图进入的请求。它的工作原理是这样的:
1. 哈希函数:布隆过滤器使用多个哈希函数,将请求的URL转换成一系列的数字。
2. 位数组:布隆过滤器内部有一个位数组,每个位置代表一个可能的URL。
3. 标记位置:当一个新的请求到来时,布隆过滤器会使用哈希函数计算出多个位置,并将这些位置标记为“是”。
4. 检查标记:如果位数组中所有标记的位置都是“是”,那么这个请求就是合法的;如果有一个位置是“否”,那么这个请求就是非法的。
这样,那些试图访问不存在的页面的请求,就会被布隆过滤器挡在门外,从而避免了缓存穿透的问题。
布隆过滤器的优势
使用布隆过滤器解决缓存穿透,有几个明显的优势:
1. 高效:布隆过滤器的查询速度非常快,几乎可以瞬间完成。
2. 空间占用小:相比于其他缓存穿透解决方案,布隆过滤器所需的存储空间更小。
3. 易于实现:布隆过滤器的实现非常简单,易于在现有的系统中集成。
布隆过滤器的局限性
当然,布隆过滤器也不是万能的,它也有一些局限性:
1. 误报:由于布隆过滤器是基于概率的,所以可能会出现误报的情况,即一个合法的请求被错误地标记为非法。
2. 删除困难:一旦某个URL被标记为存在,就很难从布隆过滤器中删除,这可能会导致一些过时的数据被错误地认为是有效的。
如何使用布隆过滤器
那么,如何在实际项目中使用布隆过滤器呢?以下是一些步骤:
1. 选择合适的哈希函数:选择多个哈希函数,以确保布隆过滤器的准确性。
2. 确定位数组的大小:位数组的大小需要根据实际需求进行调整,以确保足够的准确性和空间利用率。
3. 集成到系统中:将布隆过滤器集成到你的缓存系统中,确保每个请求都会经过过滤器的审查。
布隆过滤器是一个简单而有效的工具,可以帮助你解决缓存穿透的问题。虽然它不是完美的,但只要合理使用,就能让你的网站更加稳定、高效。下次当你遇到缓存穿透的问题时,不妨试试布隆过滤器这个神奇的小工具吧!