
Redis布隆过滤器,高效数据去重与查询加速利器
Redis布隆过滤器:大数据时代的空间魔术师
想象你是一位侦探,正在追踪一个神秘的嫌疑人。你有一堆线索,但你知道其中很多可能是重复的,甚至是错误的。你如何快速筛选出真正有用的信息,避免被大量无关紧要的数据淹没?在当今大数据时代,这个问题不仅困扰着侦探,也困扰着无数需要处理海量数据的开发者。幸运的是,有一种神奇的数据结构能够帮助你,它就是Redis布隆过滤器。
什么是Redis布隆过滤器?
Redis布隆过滤器是一种概率数据结构,它由一个很长的二进制向量和一系列哈希函数组成。它的主要功能是判断一个元素是否存在于一个集合中。与传统的数据结构相比,布隆过滤器在空间效率上有着惊人的表现,它可以在几乎不占用额外内存的情况下,完成对大量数据的快速判断。
布隆过滤器的工作原理非常巧妙。当你向布隆过滤器中添加一个元素时,会通过多个哈希函数计算出多个哈希值,并将对应的位数组位置设为1。例如,假设你有一个元素\example\,你可能会使用三个哈希函数,分别计算出三个不同的哈希值,然后将这三个哈希值对应的位数组位置设为1。这样,\example\就被成功添加到了布隆过滤器中。
当你需要判断一个元素是否存在于布隆过滤器中时,同样会通过多个哈希函数计算出多个哈希值,并检查对应的位数组位置是否都为1。如果有任何一个位置为0,则可以确定该元素不存在于集合中;如果所有位置都为1,则可能存在于集合中,但并不确定。这种机制使得布隆过滤器能够在极低的误判率下,完成对海量数据的快速判断。
Redis布隆过滤器的特点

Redis布隆过滤器具有以下几个显著特点:
1. 空间效率高:布隆过滤器在空间效率上远超传统的数据结构,它可以在几乎不占用额外内存的情况下,完成对大量数据的快速判断。
2. 查询速度快:布隆过滤器的查询速度非常快,因为它只需要进行几次哈希运算和位数组检查,就可以判断一个元素是否存在于集合中。
3. 误判率可控:布隆过滤器虽然存在误判的可能性,但误判率可以通过调整哈希函数的数量和位数组的大小来控制。通常情况下,误判率可以控制在0.1%以下。
4. 不可删除:布隆过滤器不支持删除操作,因为删除操作会影响其他元素的判断结果。不过,你可以通过创建一个新的布隆过滤器来解决这个问题。
Redis布隆过滤器的使用场景
Redis布隆过滤器在许多场景中都有着广泛的应用,以下是一些典型的使用场景:
缓存穿透防护
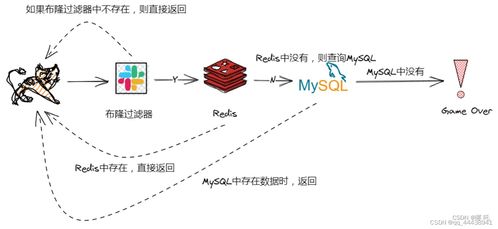
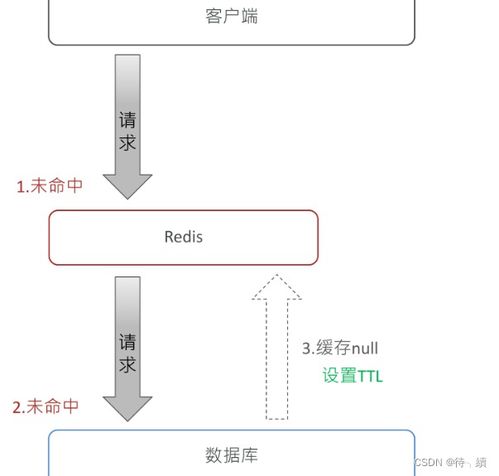
缓存穿透是指查询一条不存在的数据,缓存中没有,则每次请求都打到数据库中,导致数据库瞬时请求压力过大。布隆过滤器可以有效地防止缓存穿透,因为它可以在请求到达缓存之前,快速判断数据是否存在。如果数据不存在于布隆过滤器中,则可以直接返回,避免请求打到数据库。
例如,假设你有一个电商网站,用户经常会查询一些不存在的商品信息。如果没有布隆过滤器,每次查询都会打到数据库,导致数据库压力过大。而有了布隆过滤器,你可以在请求到达缓存之前,快速判断商品信息是否存在。如果商品信息不存在于布隆过滤器中,则可以直接返回,避免请求打到数据库。
URL去重
在爬虫系统中,布隆过滤器可以用来对抓取到的URL进行去重。爬虫系统每天会面临海量的URL数据,如果不对这些URL进行去重,会严重影响执行效率。布隆过滤器可以在几乎不占用额外内存的情况下,对URL进行去重,从而提高爬虫系统的执行效率。
例如,假设你有一个爬虫系统,每天会抓取大量的网页。如果没有布隆过滤器,每次抓取到的URL都需要存储在内存中,导致内存占用过大。而有了布隆过滤器,你可以在抓取URL之前,快速判断URL是否已经存在。如果URL已经存在,则可以跳过,避免重复抓取。
垃圾邮件过滤
垃圾邮件过滤是另一个典型的应用场景。垃圾邮件过滤系统每天会收到大量的邮件,其中很多是垃圾邮件。布隆过滤器可以用来对邮件进行快速过滤,从而提高垃圾邮件过滤系统的效率。
例如,假设你有一个垃圾邮件过滤系统,每天会收到大量的邮件。如果没有布隆过滤器,每次都需要对邮件进行详细检查,导致效率低下。而有了布隆过滤器,你可以在检查邮件之前,快速判断邮件是否可能是垃圾邮件。如果是垃圾邮件,则可以直接过滤掉,避免详细检查。
用户行为分析
在用户行为分析中,布隆过滤器可以用来对用户行为进行快速判断。例如,你可以使用布隆过滤器来记录用户访问过的页面,从而快速判断用户是否已经访问过某个页面。
例如,假设你有一个网站